Key Concepts
Introduction
One of Dagger's key aspects is cross-language instrumentation: teams can leverage their familiar languages without the need to learn a new DSL to write their CI/CD pipelines. Dagger allows this by exposing its functionality through GraphQL which serves as a low-level language-agnostic API framework for all Dagger operations.
This approach has multiple benefits:
- It enables CI/CD pipeline authors to use whichever language feels natural and intuitive to them, without having to think about interoperability.
- Even though pipelines may be written in different languages, they are all run by the same engine. So common concerns like logging, scaling, monitoring and others only need to be solved once, and can then be applied for everyone.
- Using GraphQL as a common low-level language facilitates reusability. Even if teams can't directly re-use each other's pipelines (yet), they can take advantage of the fact that they all produce the same GraphQL queries. This creates opportunities for knowledge sharing and collaboration, even across languages.
This tutorial explains the key concepts you need to use the Dagger GraphQL API.
This tutorial explains some basic GraphQL concepts in the context of the Dagger GraphQL API, but it is not intended as a full-featured GraphQL tutorial. To learn more about GraphQL and how it works, read the GraphQL tutorial.
Objects, Fields and Build Operations
To understand the Dagger GraphQL API, consider the following query:
query {
container {
from(address: "alpine:latest") {
withExec(args: ["apk", "info"]) {
stdout
}
}
}
}
This query represents a very simple Dagger pipeline. In plain English, it instructs Dagger to "download the latest alpine container image, run the command apk info in that image, and print the results of the command to the standard output device". It returns a list of the packages installed in the image:
A GraphQL schema works by defining one or more object types, and then fields (and field arguments) on those object types. The fields of an object type can themselves be objects, allowing for different entities to be logically connected with each other. API users can then perform GraphQL queries to return all or some fields of an object.
With Dagger's GraphQL API, while all of the above is true, each field in a query also resolves to a build operation. To understand this, let's dissect the query above:
- Consider the first level of the previous query:
query {
container {
from(address: "alpine:latest") {
...
}
}
}
This query requests the from field of Dagger's Container object type, passing it the address of a container image as argument. To resolve this, Dagger will initialize a container from the image published at the given address and return a Container object representing the new container image.
- Now, consider the next level of the query:
query {
container {
from(address: "alpine:latest") {
withExec(args: ["apk", "info"]) {
...
}
}
}
}
Here, the query requests the withExec field of the Container object returned in the previous step, passing it the command to be executed as an array of arguments. To resolve this, Dagger will define the command for execution in the container image and return a Container object containing the execution results.
- Finally, consider the innermost level of the query:
query {
container {
from(address: "alpine:latest") {
withExec(args: ["apk", "info"]) {
stdout
}
}
}
}
Here, the query requests the stdout field of the Container object returned in the previous step. To resolve this, Dagger will return a String containing the result of the last executed command.
Object Identifiers
In a GraphQL schema, every object exposes an id field. This ID serves to uniquely identify and retrieve an object, and is also used by GraphQL's caching mechanism.
In the Dagger GraphQL API too, objects expose an ID but here, the ID represents the object's state at a given time. Objects like Container and Directory should be thought of as collections of state, which are updated by subsequent field resolutions and whose ID represents their state at the instant of field resolution.
To illustrate this, consider the following query:
query {
host {
directory(path: ".") {
id
}
}
}
The return value of the previous query is an ID representing the state of the current directory on the host.
By using object IDs to represesent object state, Dagger's GraphQL API enables some very powerful features. For example, you can save this state and reference it elsewhere (even in a different Dagger pipeline or engine). You can then continue updating the state from the point you left off, or use it an input to another query.
To make this clearer, consider the following query:
query {
container {
from(address: "alpine:latest") {
withExec(args: ["touch", "/tmp/myfile"]) {
id
}
}
}
}
This query instructs Dagger to:
- initialize a container from the
alpine:latestimage (this resolves thefromfield) - create an empty file at
/tmp/myfileusing thetouchcommand (this resolves thewithExecfield) - return an identifier representing the state of the container filesystem (this resolves the final
idfield)
The output of this query is an identifier representing the state of the container filesystem and Dagger's execution plan.
Now, execute a second query as follows, replacing the placeholder with the contents of the id field from the previous query:
query {
container(id: "YOUR-ID-HERE") {
withExec(args: ["ls", "/tmp"]) {
stdout
}
}
}
This second query instructs Dagger to:
- initialize a container using the filesystem state provided in the ID
- run the
lscommand to list the files in the/tmp/directory (this resolves thewithExecfield) - return the output of the command (this resolves the final
stdoutfield)
This second query returns a listing for the /tmp directory.
As this example demonstrates, Dagger object IDs hold the state of their corresponding object. This state can be transferred from one query to another, or even from one Dagger instance to another. It can also be updated or used as input to other objects.
Lazy Evaluation
GraphQL query resolution is triggered only when a leaf value (scalar) is requested. In the previous example, the GraphQL API resolves the query and performs the build operations only when the stdout field is requested. Dagger uses this feature of GraphQL to evaluate pipelines "lazily".
An example will make this clearer. First, navigate to Webhook.site, a free online tool that lets you receive and log incoming HTTP requests. Obtain and copy your unique webhook URL, as shown below:
Then, execute the following query, replacing the placeholder with your unique webhook URL:
query {
container {
from(address: "alpine:latest") {
withExec(args: ["apk", "add", "curl"]) {
withExec(args: ["curl", "YOUR-WEBHOOK-URL"]) {
id
}
}
}
}
}
This query instructs Dagger to:
- initialize a container from the
alpine:latestimage (this resolves thefromfield) - add the
curlcommand-line tool to the image viaapk add(this resolves thewithExecfield) - send an HTTP request to your webhook URL using
curl(this resolves the secondwithExecfield) - return an ID representing the container state (this resolves the final
idfield)
The query returns a base64-encoded block, as explained in the previous section.
However, check the Webhook.site dashboard and you will notice that no HTTP request was sent when this query was executed. The reason is laziness: the query requests only an ID and, since resolving this does not require the commands to be executed, Dagger does not do so. It merely returns the container state and execution plan without actually executing the plan or running the curl command.
Now, update and execute the query again as follows:
query {
container {
from(address: "alpine:latest") {
withExec(args: ["apk", "add", "curl"]) {
withExec(args: ["curl", "YOUR-WEBHOOK-URL-HERE"]) {
stdout
}
}
}
}
}
This time, Dagger both prepares and executes the plan, because that is the only way to resolve the stdout field. Check the Webhook.site dashboard and the HTTP request sent by the curl command will be visible in the request log, as shown below:
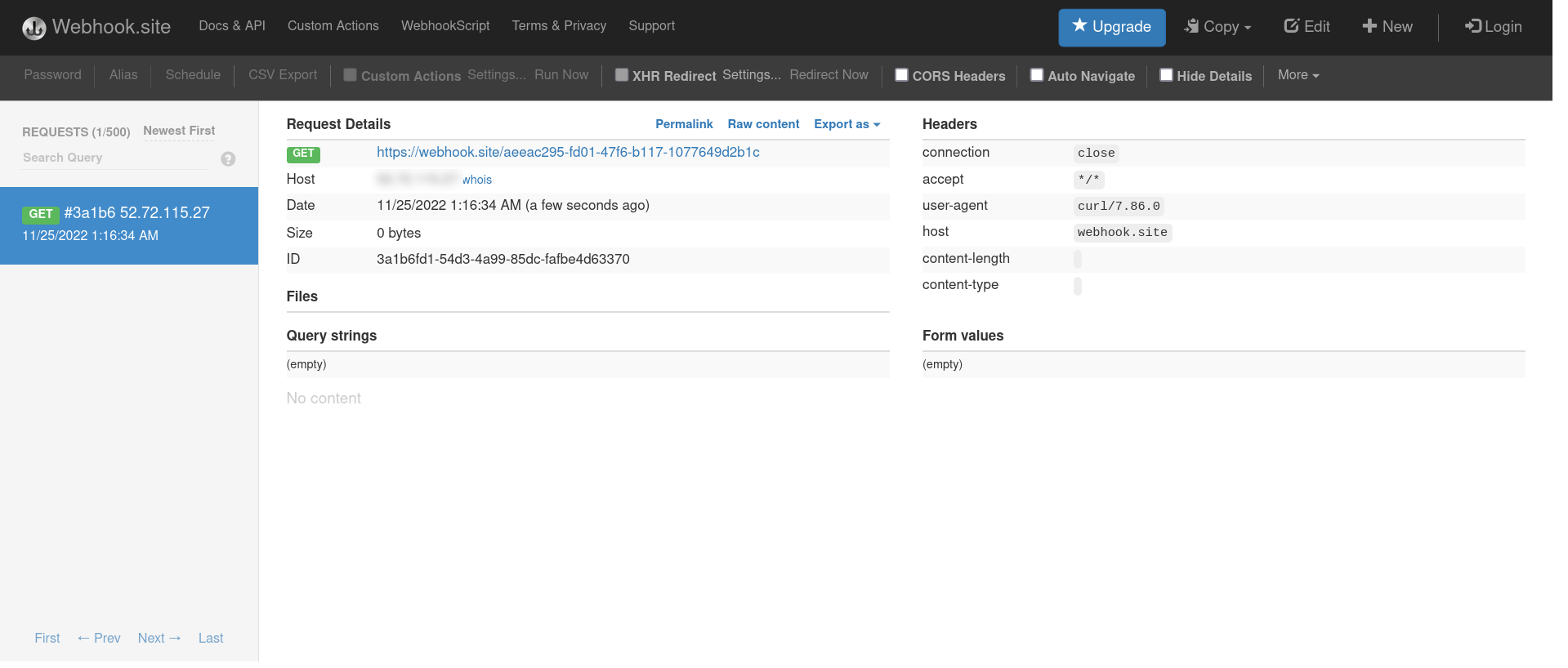
This example demonstrates the lazy evaluation model in action. The client requests data, and the Dagger GraphQL API returns that data. If executing a command is necessary to return that data, it will do so; if not, it will not.
Lazy evaluation is a key advantage of GraphQL. It allows users to write queries (or code, if using an SDK) in a procedural manner, and resolves those queries only when necessary to return data to the user. Dagger leverages this lazy evaluation model to optimize and parallelize query execution for maximum speed and performance.
Conclusion
This tutorial introduced you to the Dagger GraphQL API. It explained the reasons for using GraphQL and walked you through the components of a Dagger GraphQL API query. It also explained how Dagger leverages some of GraphQL's features, such as unique identifiers and lazy evaluation, to improve the portability and speed of CI/CD pipeline execution.
Use the API Reference to learn more about the Dagger GraphQL API.