Understand CI Architecture Patterns for Dagger on Kubernetes
Introduction
This guide outlines how to set up a Continuous Integration (CI) environment with the Dagger Engine on Kubernetes. It describes and explains a few architecture patterns and components, together with optional optimizations.
Assumptions
This guide assumes that you have:
- A good understanding of how Kubernetes works, and of key Kubernetes components and add-ons.
- A good understanding of how Dagger works. If not, read the Dagger Quickstart.
Architecture Patterns
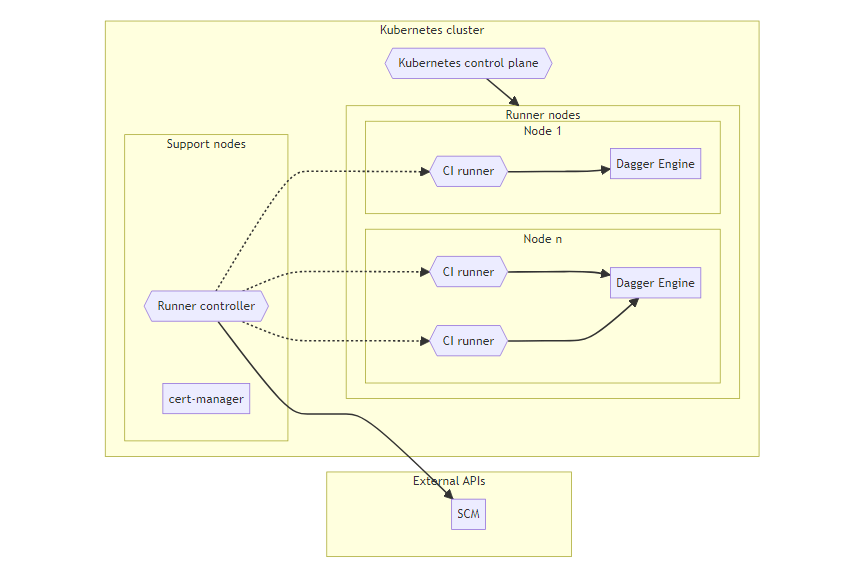
Base pattern: Persistent nodes
The base pattern consists of persistent Kubernetes nodes with ephemeral CI runners.
The minimum required components are:
- Kubernetes cluster, consisting of support nodes and runner nodes.
- Runner nodes host CI runners and Dagger Engines.
- Support nodes host support and management tools, such as certificate management, runner controller & other functions.
- Certificates manager, required by Runner controller for Admission Webhook.
- Runner controller, responsible for managing CI runners in response to CI job requests.
- CI runners are the workhorses of a CI/CD system. They execute the jobs that are defined in the CI/CD pipeline.
- Dagger Engine on each runner node, running alongside one or more CI runners.
- Responsible for running Dagger pipelines and caching intermediate and final build artifacts.
In this architecture:
- Kubernetes nodes are persistent.
- CI runners are ephemeral.
- Each CI runner has access only to the cache of the local Dagger Engine.
- The Dagger Engine is deployed as a DaemonSet, to use resources in the most efficient manner and enable reuse of the local Dagger Engine cache to the greatest extent possible.
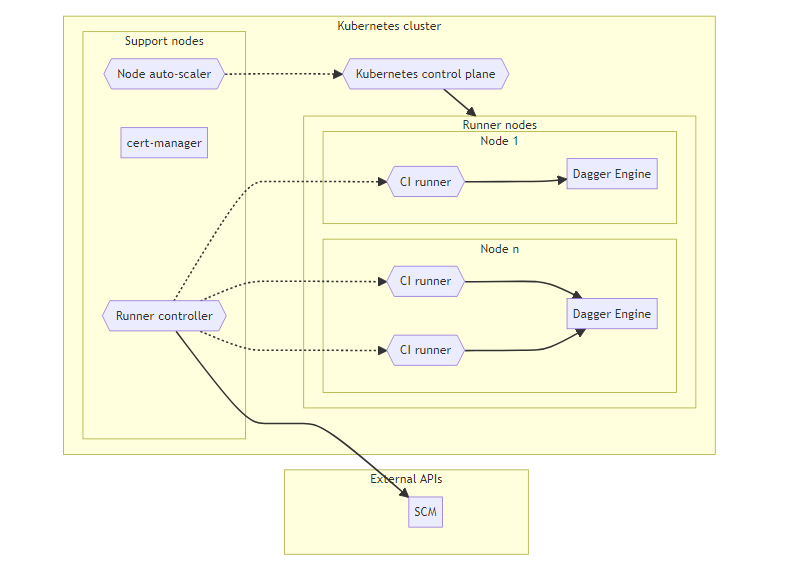
Optimization 1: Ephemeral, auto-scaled nodes
The base architecture pattern described previously can be optimized by the addition of a node auto-scaler. This can automatically adjust the size of node groups based on the current workload. If there are a lot of CI jobs running, the auto-scaler can automatically add more runner nodes to the cluster to handle the increased workload. Conversely, if there are few jobs running, it can remove unnecessary runner nodes.
This optimization reduces the total compute cost since runner nodes are added & removed based on the number of concurrent CI jobs.
In this architecture:
- Kubernetes nodes provisioned on-demand start with a "clean" Dagger Engine containing no cached data.
- Cached build artifacts from subsequent runs will persist only for the lifetime of the runner node.
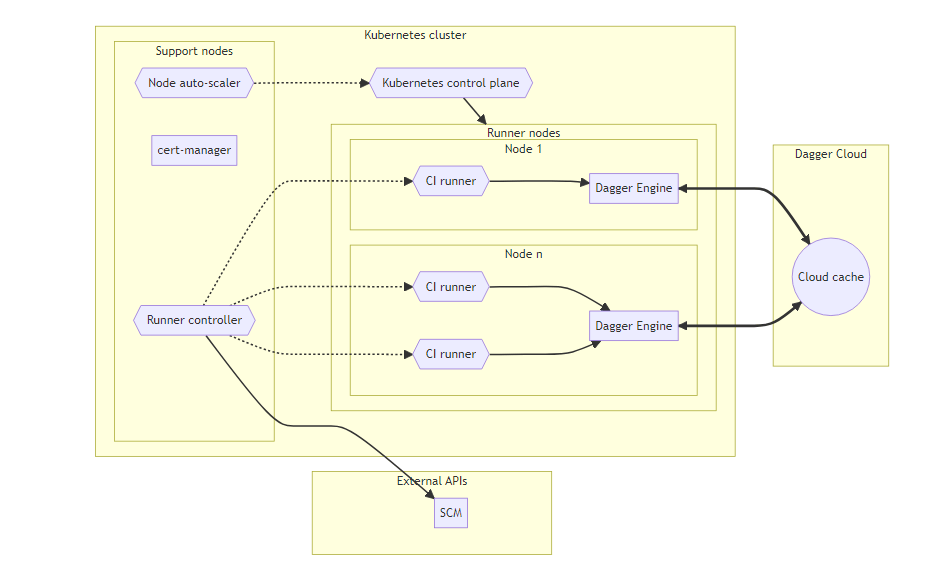
Optimization 2: Shared Cloud Cache
The previous pattern makes it possible to scale the Dagger deployment, but comes with the following trade-offs:
- Runner nodes are automatically de-provisioned when they are not needed. During de-provisioning, the Dagger Engines get deleted too. As a result, data and operations cached in previous runs will be deleted and subsequent runs will not benefit from previous runs. To resolve this, the cached data and operations are stored in a cloud caching service and made available to new Dagger Engines when they are provisioned.
- The deployment will only scale to a certain point, given that each Dagger Engine can only scale vertically to provide better performance. In order to make the system horizontally scalable, a caching service makes the same data and operations available to as many Dagger Engines as needed.
In this architecture:
- A shared cloud cache stores data from all Dagger Engines running in the cluster.
- Auto-provisioned nodes start with access to cached data of previous runs.
Recommendations
When deploying Dagger on a Kubernetes cluster, it's important to understand the design constraints you're operating under, so you can optimize your configuration to suit your workload requirements. Here are two key recommendations.
Runner nodes with moderate to large NVMe drives
The Dagger Engine cache is used to store intermediate build artifacts, which can significantly speed up your CI jobs. However, this cache can grow very large over time. By choosing nodes with large NVMe drives, you ensure that there is plenty of space for this cache. NVMe drives are also much faster than traditional SSDs, which can further improve performance. These types of drives are usually ephemeral to the node and much less expensive relative to EBS-type volumes.
Runner nodes appropriately sized for your workloads
Although this will obviously vary based on workloads, a minimum of 2 vCPUs and 8GB of RAM is a good place to start. One approach is to set up the GitHub Actions runners with various sizes so that the Dagger Engine can consume resources from the runners on the same node if needed.
Conclusion
This guide described a few common architecture patterns to consider when setting up a Continuous Integration (CI) environment using Dagger on Kubernetes.
Use the following resources to learn more about the topics discussed in this guide:
- See an example of running Dagger on Amazon EKS with GitHub Actions Runner and Karpenter
- Dagger Cloud
- Dagger GraphQL API
- Dagger Go, Node.js and Python SDKs
If you need help troubleshooting your Dagger deployment on Kubernetes, let us know in Discord or create a GitHub issue.